| https://www.next-finance.net/fr | |
|
Stratégie
|

Machine Learning : Choisir pour vous le meilleur régime !
Le développement des techniques de Machine Learning et du « big data » a permis d’appliquer aux séries financières des modèles mathématiques sophistiqués pour identifier les régimes de marché. Tout cela constitue un champ d’innovation pour l’industrie de la gestion d’actifs.
Article aussi disponible en :
English ![]() |
français
|
français ![]()
Les investisseurs ont depuis bien longtemps admis que les marchés sont fréquemment assujettis à des changements de régimes. En effet ils oscillent souvent entre des phases de croissance marquées par de faibles volatilités et des phases de paniques caractérisées par des performances négatives et une volatilité extrême. Ces changements de régimes sont évidemment liés à des évènements économiques (crise des subprimes, crise de la dette, …) ou sanitaires (crise de la covid 19) et représentent un risque systématique majeur pour les portefeuilles. Ainsi, savoir les identifier permet de protéger les portefeuilles de risques extrêmes et même de tirer profit de ces évènements. Ils permettent aussi d’enrichir les connaissances sur les mécanismes du changement de régimes et de fait les modèles d’investissement pour mieux aborder les crises suivantes. Fort de ces constats, nous avons développé de nouveaux outils de détection des changements de régimes basés des techniques de machine Learning (apprentissage automatique) avec un double objectif : détecter les périodes risk on / risk off sur le marché dans une approche performance absolue, mais aussi identifier les régimes favorables aux différents facteurs de style sur les marchés actions (Momentum, Low volatilité, croissance, Value, size,..) dans une approche benchmarkée.
La problématique des changements de régimes a été largement abordée dans la littérature académique. Dans une étude publiée en 1999 sur la turbulence des marchés, Chow, Jacquier, Kritzman, and Lowry (1999) ont justifié l’existence de ces régimes. En 2002, Ang et Bekaert ont démontré que dans les régimes de forte volatilité, les corrélations entre les actifs augmentent fortement et la diversification au sein des portefeuilles n’est pas effective. En 1998, Clarke et de Silva ont montré que dans un monde avec plus d’un régime, il existe d’avantage d’opportunités pour les investisseurs qui adaptent leurs expositions en fonction des régimes de marché.
Le développement des techniques de Machine Learning et du « big data » a permis d’appliquer aux séries financières des modèles mathématiques sophistiqués ( « Hidden Markov switching model » que nous verrons plus loin) pour identifier les régimes de marché. Tout cela constitue un champ d’innovation pour l’industrie de la gestion d’actifs.
Les techniques de « Machine learning », qui se basent sur des modèles statistiques ou mathématiques en général, sont un domaine de l’intelligence artificielle qui permet d’identifier et de caractériser les liens pouvant exister au sein d’un large ensemble de données classiques (séries temporelles) comme alternatives (images, textes, flux d’informations, requêtes dans les réseaux sociaux, données transactionnelles, géolocalisation, etc.). Le « machine learning » est constitué de 2 parties : une partie apprentissage au cours de laquelle le modèle choisi va apprendre les relations entre les variables et une partie application dans laquelle le modèle va mettre en évidence ces relations et répondre à la problématique posée.
Aussi, en fonction de la nature des données, les méthodes statistiques utilisées en machine learning sont divisées en quatre branches :
- L’apprentissage supervisé pour les données labellisées (informations sur la donnée fournie) ;
- L’apprentissage non-supervisé sur des données brutes ;
- L’apprentissage profond, basé sur la réplication d’un réseau de neurones et l’apprentissage en couches ;
- Des approches mixtes regroupant notamment l’apprentissage renforcé, semi-supervisé ou encore l’apprentissage actif.
« Indissociable du Big Data, l’apprentissage automatique compte quatre points forts. L’approche s’intéresse à la prévisibilité hors échantillon plutôt qu’à l’évaluation de la variance dans l’échantillon. Elle s’appuie sur des méthodes de calcul destinées à éviter de se fier à des hypothèses potentiellement irréalistes. Elle est adaptée aux interactions non linéaires, hiérarchiques et non continues dans un espace à haute dimension. Enfin, elle peut dissocier la recherche de variables explicatives et de la recherche des relations qui peuvent exister entre ces variables », explique David Usemma, analyste quantitatif au sein de l’équipe de recherche de CPR AM.
S’il y a quelques années encore, l’apprentissage automatique était cantonné à quelques domaines de la finance comme l’évolution à court-terme des prix de marché, l’exécution des transactions et la fixation des notations de crédit, son expérimentation s’est depuis considérablement élargie. « Le machine learning pourrait potentiellement remodeler nos idées reçues sur les primes de risque des actifs et reconfigurer les pratiques de notre industrie - du profilage des clients à l’allocation d’actifs, en passant par la sélection de valeurs et la gestion des risques », souligne David Usemma.
Selon lui, les approches d’apprentissage automatique peuvent servir à la production de signaux d’alpha utiles dans le cadre des processus de sélection des titres, soit à partir d’une série de facteurs prédéfinis, soit sur la base de signaux d’entrée provenant de données existantes ou nouvellement trouvées.
De plus en plus, l’apprentissage automatique joue également un rôle clé dans l’analyse et l’intégration des données ESG via le « Natural Language Processing » et le « Topic Modelling » qui permettent l’analyse des rapports d’entreprise, des médias et autres supports pour identifier les controverses et les engagements des entreprises en matière d’impact climat, environnemental, éducation ou autre.
CPR AM privilégie l’apprentissage automatique pour mieux appréhender les changements de régime de marché et adapter ses stratégies de portefeuille au bénéfice des investisseurs. « Notre objectif est de fournir un outil robuste qui améliorera la visibilité des gérants en charge de nos solutions de gestion thématiques et quantitatives », confie David Usemma.
Afin d’observer les changements de régimes de marché dans des séries temporelles, l’équipe de recherche de CPR AM a recours à des chaînes de Markov à états cachés (hidden Markov model ou HMM). Ce modèle statistique développé dans les années 60 a depuis été largement appliqué en apprentissage automatique sur des problématiques d’identification : reconnaissance vocale, reconnaissance de l’écriture manuscrite, analyse des séquences de gènes. C’est en 1989 que Hamilton propose l’utilisation du modèle « Markov switching model » pour identifier les changements de régimes en finance. Pour comprendre ce modèle voici un exemple très simple qui permet de l’illustrer. Imaginez une personne dont nous suivons l’électrocardiogramme à distance et les données nous sont envoyées avec un certain délai. Lorsque la personne dort, nous observons une moyenne basse de battements cardiaques et une faible volatilité. Cependant, lorsque la personne est éveillée, la moyenne des battements est plus élevée et la volatilité est forte. Ainsi sans voir la personne, et uniquement à partir de ces données nous pouvons raisonnablement conclure dans quel état est la personne endormie ou éveillée. Ces données cardiaques suivent un modèle de markov à états cachés et à chaque instant, selon le régime on visualise les données associées. Dans le cadre des séries financières, les observations peuvent être les rendements, et les régimes BULL, BEAR, CRISE sont les états cachés.
Trouver le bon algorithme est en partie une question d’essais et d’erreurs. Les scientifiques expérimentés ont souvent du mal à dire si un algorithme fonctionnera sans l’avoir essayé. Entre autres facteurs, le choix dépend de la taille et du type de données traitées, ainsi que des informations recherchées. « Il existe des dizaines d’algorithmes d’apprentissage automatique. Chacun suit une méthode différente et il n’y en a pas un qui surpasse les autres sur tous types de données. Certains modèles peuvent sembler bons lors d’un backtest, mais donner de mauvais résultats sur des données hors échantillon. La stabilité des prévisions est donc un défi ! », explique David Usemma.
Après avoir analysé plusieurs algorithmes, l’équipe de recherche de CPR AM a fondé son choix sur l’algorithme de maximisation de vraisemblance Baum-Welch (développé par Bilmes en 1998), dans la phase d’apprentissage pour identifier et caractériser les régimes de marché. Les tests menés au cours des neuf derniers mois pour identifier les basculements de marché se sont révélés concluants.
« Nous avons travaillé sur des séries financières de performances de marché actions et de spreads de crédit. L’historique de série remontait jusqu’au milieu des années 90 pour les marchés actions et au début des années 2000 sur le crédit, afin de permettre au modèle d’apprendre des crises précédentes », détaille David Usemma. En faisant référence à l’actualité récente, sur le marché Actions, le régime bascule le 21 février de marché haussier (performance positive, volatilité faible) à marché baissier - performance nulle. Il passe dans les jours suivants à marché en crise (performance négative, forte volatilité).

- Etats de l’indicateur de changement de régimes, Source : Recherche CPR AM
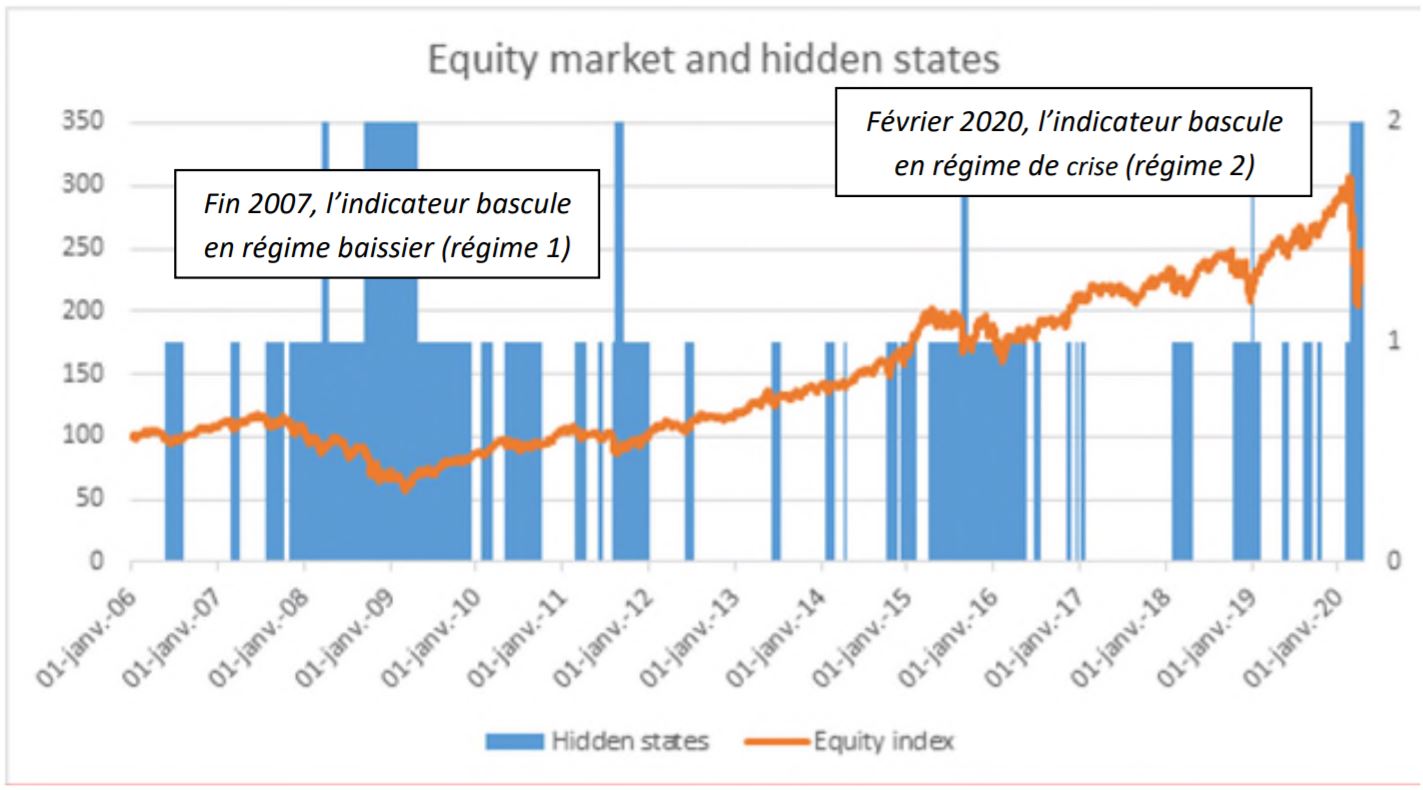
« L’indicateur HMM servira non seulement à identifier les régimes de marché bull, bear ou crise sur les marchés actions ou crédit, mais aussi à piloter les transitions entre les facteurs (value vs défensifs par exemple) des portefeuilles de nos solutions d’investissement quantitatives, comme le fonds CPR Equity All Regimes. Sur les gestions thématiques, l’identification des retournements de tendance permettra de protéger les fonds face à des risques de perte extrêmes », conclut David Usemma.
En définitive, le machine learning est une boîte à outils formidable qui permet aux équipes de CPR AM de renforcer leurs convictions notamment sur les régimes de marché et d’innover en repensant les stratégies d’investissement avec des approches novatrices. Après la revue des changements de régimes, viendra certainement la revue des modèles factoriels et leur intégration dans les portefeuilles de gestion.
Pour l’ensemble de ces travaux, la collaboration étroite entre les équipes de Recherche et de gestion est clé. « Un bon indicateur est celui qui crée plus de valeurs que ne coûte la mise en place de la stratégie qu’il conditionne. Il faut donc, lors des tests des différents signaux, créer un environnement équivalent à celui du marché en intégrant l’ensemble des frais liés aux transactions (brokers, impôt de bourse, effet marché, liquidité), et rendre ainsi la valeur ajoutée créée dans les back-tests « investissable », c’est-à-dire « nettoyée » des frais du turnover de sa mise en place. Cette mise en perspective permet souvent de définir la fréquence de calcul optimale des différents signaux », explique Cyrille Collet, directeur de la gestion action quantitative chez CPR AM.
David Usemma , Noémie Hadjadj-Gomes , Juillet 2020
Article aussi disponible en :
English ![]() |
français
|
français ![]()
Focus

Stratégie Révolution indicielle dans les Hedge funds
Une critique courante des modèles factoriels repose sur le fait qu’ils ne "répliquent que le bêta" - pas l’alpha pur que recherchent les allocataires. Cette critique est antérieure à l’appréciation des rotations factorielles. L’analyse d’Andrew Beer, dirigeant et co-fondateur de (...)
Actualité
Analyse
Publicité
Zoom
-
Crise européenne
-
Actifs cachés
-
Allocation, Multi-As
-
Smart Beta
-
Stratégies sur divide
-
Alternative Risk
-
Infrastructure
-
Chine
-
Gestion Obligataire
-
Gestion Action
-
ETF Actions américain
-
Actions Thématiques
-
Special Investisseme
-
Économie bleue : (...)
-
Les thématiques (...)
-
L’IMPACT CHEZ CPR
-
ACTIONS THÉMATIQUES
-
La voie vers l’écono
-
Comment les investis
-
Assurer l’avenir (...)
-
Forex
-
Chronique de Mory
-
Carnets d’Éclairages
-
Solvency II
-
Managed Accounts
-
Les Derivés Total
-
Contrats à terme (...)
-
La Dette Française
-
Recherche Quantitati
-
Le marché français
-
Flux RSS
| Fil d'actualité | |
| Emplois & Stages | |
| Formations |
|
|
Site | English | Francais | Mobile | Facebook | Twitter |